

Nectar Daloglou‘s post on 99 Ways to Crash Your Database was so popular, we thought we’d bring you even MORE ways to ruin the upcoming holidays!
The dreaded “abnormal shutdown”
Sound familiar? Pretty much anyone who supports an OpenEdge database has experienced this.
WDOG 6: (2522) User 22 died holding 1 shared memory locks.
WDOG 22: (5029) SYSTEM ERROR: Releasing 1 multiplexed latch. latchId:
3096224748304416
BROKER 0: (2249) Begin ABNORMAL shutdown code 2
Typically this happens when an over-zealous administrator kills a shared memory Progress client. And while there is no 100% safe way to kill an OpenEdge process connected to shared memory, there are definitely a few unsafe methods!
Kill – kill – kill
The UNIX kill command sends a signal to a running process, and, except in the case of certain untrappable signals, the OpenEdge client’s signal handler reacts accordingly.
For example, if the signal sent is SIGUSR1, a protrace file is created. This is what $DLC/bin/proGetStack does.
But if you send an untrappable SIGKILL (the dreaded “kill -9”), then the process simply vanishes, and the watchdog is left to cleanup the mess it leaves behind. If that mess included shared memory latches, then the database will initiate an abnormal shutdown.
Note that the somewhat confusing message “(298) KILL signal received.” actually indicates that a SIGTERM signal was sent. It does not indicate that “kill -9” was sent. Kill -9 is not trappable so there is no way to notice it and then write a message about it to the .lg file.
FYI: ProTop includes a free tool called killprosession.sh, which can be used to terminate an OpenEdge client process on UNIX while minimizing the risk of a crash.
Windows end task
Yowzer…this is the same as a kill -9 on UNIX. There is no equivalent to the signal handler in Windows, so an end task is immediately fatal. If the process was holding a shared memory resource, the watchdog or broker may force an abnormal shutdown to preserve the database’s integrity.
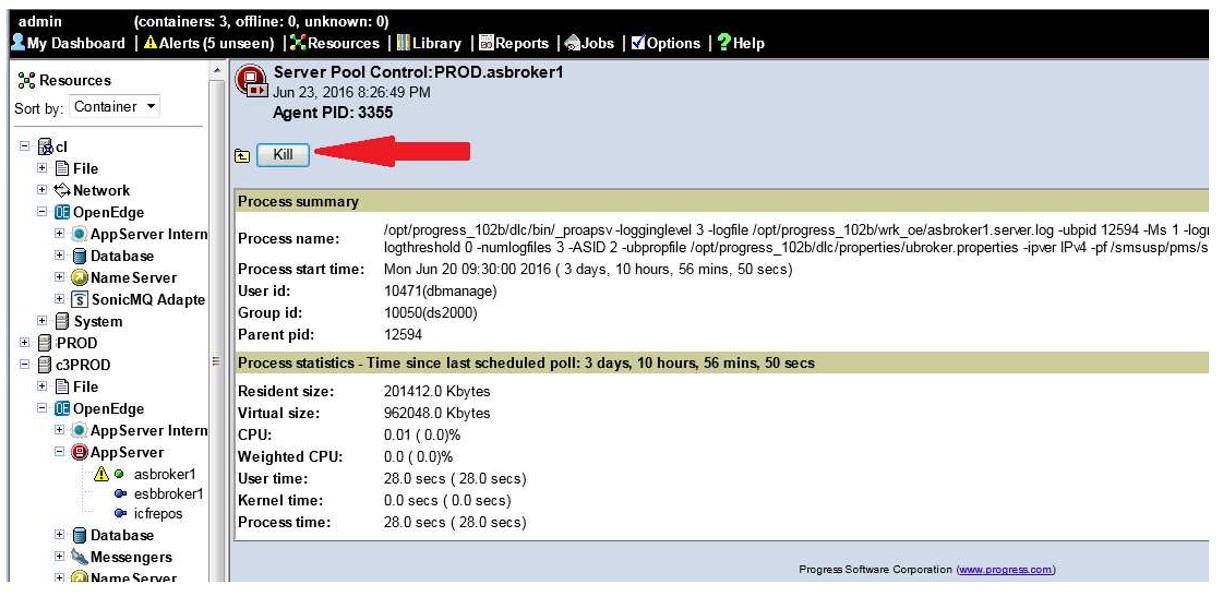
Killing an AppServer agent from OpenEdge Management
Don’t be fooled into thinking that this is more safe! If the agent is connected to database shared memory, the same risks apply.
On Windows, the process is terminated with the wmic terminate command. See the previous section on Windows end task.
On UNIX, the SIGKILL signal is sent.
Closing a CMD window
Do I sound like a broken record? Again, this is the same as an “end task”.
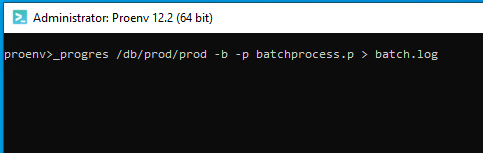
If you close this CMD window, the _progres.exe process will be terminated.
Windows logout – BONUS CRASH!!
When a user logs out of a Windows session, ALL its processes are terminated.
This means that if you start a batch process from Task Scheduler using mydomain\myuser, then remote desktop to that same server using mydomain\myuser, when you logout, the scheduled task will also be terminated. Make sure to always start scheduled tasks with a dedicated user account.
There are also situations when you may need to restart a replication server or agent or other helper process. Do not start these from the command line, and certainly do not use a user account. Always use a background launcher like Task Scheduler or srvany.exe, and use the same user account as was used to start the database.
No more empty fixed-length AI extents
If your database is configured with fixed-length AI extents, and your AI rotation process fails, your database will crash or stall when the last AI extent fills.
At WSS, we generally advocate for all variable length AI extents because a) the performance penalty is negligible for 99% of the 4000+ databases that ProTop monitors; and b) when there is a problem with AI rotation, the currently busy variable length AI extent will simply continue to grow into existing available space, giving the DBA a bit more time to resolve the issue before the database crashes or stalls.
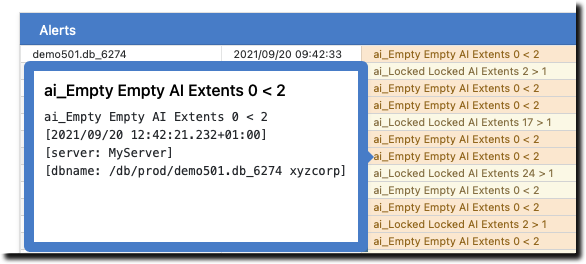
It is important to note that online backups will fail if there are no available empty AI extents, as the online backup requires an AI file switch, which is impossible if there are no empty AI extents available. More often than we can count, we’ve come across situations where database backups have failed for weeks or months without anyone noticing. Are you monitoring your backups? ProTop uses the dbBkupFull metric to alert on the elapsed time since the last good backup.
Large files
If you are running Workgroup database, or forget to enable large files on your Enterprise database, there is a hard size limit of 2 GB for all database files. AI files, BI files, data files…all will stop growing at 2 GB and crash the database if no other file is available. Please remember to enable large files!
The good news is that large files are enabled by default for OpenEdge 12 Enterprise databases.
Crash or AI stall?
In a perfect world, all databases would use the -aistall parameter and all support staff would know how to recognize and act when confronted with a database AI stall. The unfortunate reality is that often, the database hangs, no one understands why, and the simplest solution is to kill the database broker or reboot the server.
If you decide to use -aistall, you must a) have appropriate monitoring in place; and b) have a written procedure available describing what to do when an AI stall event occurs.
Locked AI extents
OpenEdge replication adds another dimension to the “no more empty AI extents” risk: locked AI extents.
The AI rotation and archival process might be functioning correctly, but an AI extent cannot be marked as empty until its contents have been successfully replicated to the OE replication target databases. Practically, this means that in addition to monitoring the number of empty and full AI extents, you should also monitor the number of locked extents and the status of the replication server and agents. The command ” dsrutil <db> -C status -detail” should return 6021 on the source database and 3049 on the target database(s). Important note: always monitor both the source and the target(s). Sometimes one or the other lies!
Speaking of OpenEdge replication…
OpenEdge replication introduces another important metric to monitor, lest it affect your system availability: full pica buffers. The DB Service Queue (commonly called the pica buffers because of the -pica startup parameter) contains pointers to AI notes in the AI files that have not yet been replicated to the target database(s). If the DB Service Queue fills, modifications to the database are halted until space becomes available. The PicaUsedPct metric in ProTop keeps track of DB Service Queue usage.
What will you be doing over the holidays?
The way we see it, you have two choices: Learn from other DBAs mistakes or spend your holidays executing your DR plan. Deploying the best OpenEdge Monitoring and Advanced Alerting Tool in the Galaxy probably wouldn’t hurt either.
Questions? Confused? Ask the experts.

