

From Big Iron to a “Commodity Server”
In this real-life case study of the migration of a 1,500+ user system from Solaris to Linux, we examine the question of how large a user load a Linux Server can support.
Here are some of the points we cover:
- The reasons for the migration
- The tools used to benchmark and validate the target system
- Discuss tuning adjustments and changes
- The methodology used to ensure a successful migration
- Share the results of this project
- Talk about where projects like this might go in the future!
The Starting Point
A large, international distribution center with approximately fifteen hundred users all over Latin America running OpenEdge 11.3 on Solaris. Almost all of the users are “green screen” TTY connections. There is a “web store” and various bolt-ons. A GUI application transformation project is underway.
Hardware In Place
The production server was a SUN M5000, introduced in 2007, live in 2010. The configuration was forty-eight cores @ 2.5GHz, 128GB RAM, and ten U of rack space. The list price, stripped, was $150,000. Today you can find one on eBay for a few thousand dollars.

The database replication target serverwas a SUN V890. First shipped in 2001, EOL 2009. Configured with sixteen cores @ 1.5GHz, 64GB RAM, and seventeen U of rack space. List price, stripped, was $50,000.
The application servers were NetApp Filers– expensive, proprietary, and slow, without appropriate storage. You couldn’t pay me to take one.
Pain Points
- Expensive, proprietary, aging servers and storage
- No in-house Solaris or NetApp expertise. Inadequate support from the hardware vendors
- Worst of all, business growth limited by the hardware
Goals
Business goals were to reduce capital expense and operating costs (power, data center space, specialized staff). Remove any growth limits imposed by system restrictions.
Technically, we aimed to avoid proprietary systems and replace with commodity hardware. This would allow a reduced footprint of the systems and leverage easily found admin skills. Improvement of DR capabilities was a goal, and we considered cloud platforms.
The Plan
Use Linux (RHEL) on Intel Servers, focusing on FAST cores. With no need for lots of cores, we ended up with 4×6 = 24, plus HT, including on-board FusionIO SSD storage. No separate fileserver for the database. Lots of RAM – 512GB, and no virtualization. We considered client/server versus shared memory. System performance-tested well, but we deferred that aspect of the project to the additional cost of client networking licenses. Also thought over cloud computing but chose to wait until we have more confidence in Intel hardware scalability.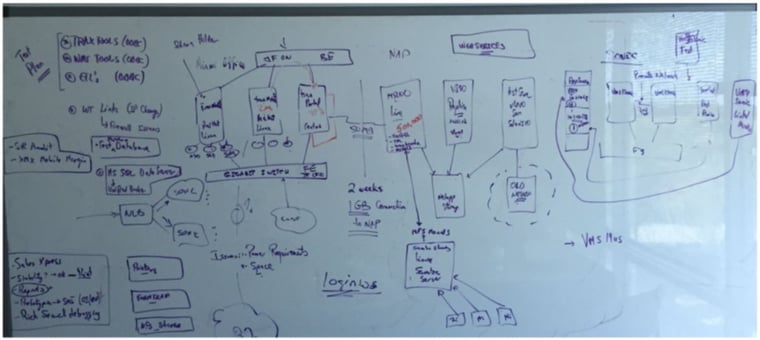
Challenges
Application testing. The initial port was easy, the application vendor supports Linux, but “the devil is in the details,” and there were many customizations. Testers were in limited supply.
There were many unknowns regarding retiring the old system to make room in the data center for the new gear. Network bandwidth between the data center and offices was a challenge since, initially, we installed the new equipment in an office.
Difficulties existed in scheduling significant downtime for the production system.
The biggest challenge of all? Will it work? Can Linux support fifteen hundred to two thousand users on Intel hardware? How many record reads/sec? Simultaneous users? CPU and memory? Numa? Network constraints?
Historical Data
Luckily, we had historical data, so we know what our main targets are:
- One thousand TRX/sec
- Five hundred thousand record reads/sec
- Two hundred simultaneous users
- At a minimum, we had to be able to hit those metrics reliably. And everyone expects significant improvements.
Benchmarks
The ATM benchmark is well known and provides data on transaction throughput in the database. Readprobe and Spawn are benchmarks that are available as part of the free ProTop download, and measure read throughput and the ability to spawn thousands of processes.
- ATM to ensure we can write data fast enough
- Readprobe to verify we can read data quickly enough
- Spawn to make sure that everyone can log in and perform useful work
Benchmark Results
- ATM not very interesting, bunker-tested to death; the server is plenty fast enough
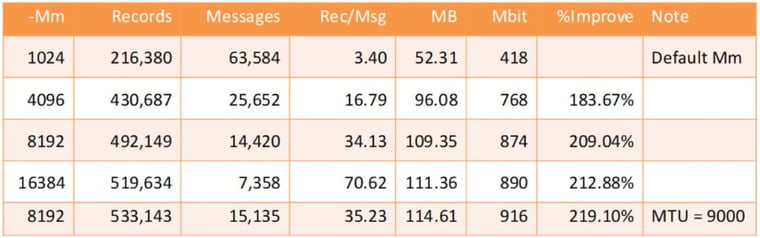
- Readprobe run twenty plus iterations. The fastest configuration was with -spin 7500
- Client/Server:
Next Steps
Stay tuned for Part Two !!

