

Why are Collections practical when developing Progress OpenEdge applications?
Do you have experience with any object-oriented programming language? Then chances are you have already encountered Collections. OpenEdge has them too. Learn why they are a helpful addition to your OpenEdge programming toolbox.
A little background
Progress OpenEdge already had a limited implementation of Collections with the OpenEdge.Core.Collections package. At the beginning of 2022, Progress OpenEdge version 12.5 was released, with a built-in list collection construct that any ABL application can use. Collections offer multiple advantages in the development of object-oriented applications. This blog post explains what Collections are and what benefits they bring when developing your Progress OpenEdge applications and how to enable their full potential.
What is a Collection?
According to Technopedia: "In programming, a collection is a class used to represent a set of similar data type items as a single unit. These unit classes are used for grouping and managing related objects."
A collection can be considered a temp-table, which stores objects of the same type instead of recording data in fields. On top of that, a collection is an object, meaning it has associated methods that allow easy manipulation of the stored objects.
For Progress OpenEdge version 12.5, the 'List' type collection has been implemented by adding six built-in classes and interfaces:
- Progress.Collections.ICollection<T> interface
- Progress.Collections.IIterable<T> interface
- Progress.Collections.IIterator<T> interface
- Progress.Collections.IList<T> interface
- Progress.Collections.List<T> class
- Progress.Collections.ListIterator<T> class
Why are Collections useful in object-oriented applications?
There are several advantages of using Collections for list creation in your code:
- In object-oriented applications, Collections eliminate the need to use temp-tables or write data structures, reducing developer effort and code bloat;
- They simplify code syntax and will be immediately familiar to those who are used to writing object-oriented code;
- Collections can also be used to serialize your data structures, allowing for easy interoperability between Progress OpenEdge and other technologies. Serialization converts an object into a) a stream of bytes to be stored in memory; b) a file to be recreated elsewhere when needed. So, if your application is split into multiple parts with different technologies, Collections can significantly reduce the effort required to set up data transfer between those other parts.
.png?width=700&height=180&name=Progress_banner_700x180%20(1).png)
What are the basics of a collection?
The code snippet below shows the basics of working with "List" type Collections. It includes creating the list, adding objects and using the "Iterator" class to iterate through the stored objects.
BLOCK-LEVEL ON ERROR UNDO, THROW.
VAR Progress.Collections.List<Order> orderList.
VAR Progress.Collections.IIterator<Order> orderIterator.
VAR order AnyOrder.
// Create the list
orderList = NEW Progress.Collections.List<Order>().
FOR EACH Order NO-LOCK WHERE Order.SalesRep = "HXM":
// Add elements to the list
orderList:Add(NEW Order(Order.OrderNum)).
END.
// Retrieve the first element from the list
AnyOrder = orderList:Get(1).
// Replace the first element in the list
orderList:Set(2, NEW Order(10000)).
// Remove the second element from the list
orderList:RemoveAt(3).
// Print out some information
MESSAGE "orderList info"
orderList:Count
orderList:Contains(AnyOrder)
orderList:IndexOf(AnyOrder)
orderList:Get(4):orderStatus.
// Iterate over the entries in the list
orderIterator = orderList:GetIterator().
REPEAT WHILE orderIterator:MoveNext():
orderIterator:Current:calcItems().
orderIterator:Current:calcTotalPrice().
END.
DEFINE VARIABLE myFileOutStream AS Progress.IO.FileOutputStream.
DEFINE VARIABLE mySerializer AS Progress.IO.JsonSerializer.
mySerializer = NEW Progress.IO.JsonSerializer(FALSE).
/* Serialize object */
myFileOutStream = NEW Progress.IO.FileOutputStream("OrderList.json").
mySerializer:Serialize(orderList, myFileOutStream).
myFileOutStream:Close().
/* Also, possible to serialise to memptr */
DEFINE VARIABLE memptrVar AS MEMPTR NO-UNDO.
DEFINE VARIABLE myMemoryOutStream AS Progress.IO.MemoryOutputStream.
myMemoryOutStream = NEW Progress.IO.MemoryOutputStream().
mySerializer:Serialize(orderList, myMemoryOutStream).
memptrVar = myMemoryOutStream:Data.
Performance testing: temp-table vs collection
Together with colleagues from Baltic Amadeus, we did some limited performance testing to compare temp-table versus collection performance. Tests were performed on personal workstations on both Windows and Linux operating systems. Some of these tests involved reading large amounts of data from CSV files, adding them to temp-tables/lists, and performing operations with these data structures. The duration of each process was measured in milliseconds.
Overall, we found the performance to be comparable. However, in some cases, there were noticeable differences in performance between the two operating systems. Unfortunately, with the limited scope of testing, we cannot say whether this is an optimization problem, some bug, a quirk of the operating system, or the hardware we were using.
Worth mentioning as well is that there is a bug in version 12.5, which limits the maximum number of objects in the list collection (in our case, this was ~4105 objects). This has been fixed in version 12.5.1.
Here is a table showing the test we conducted:
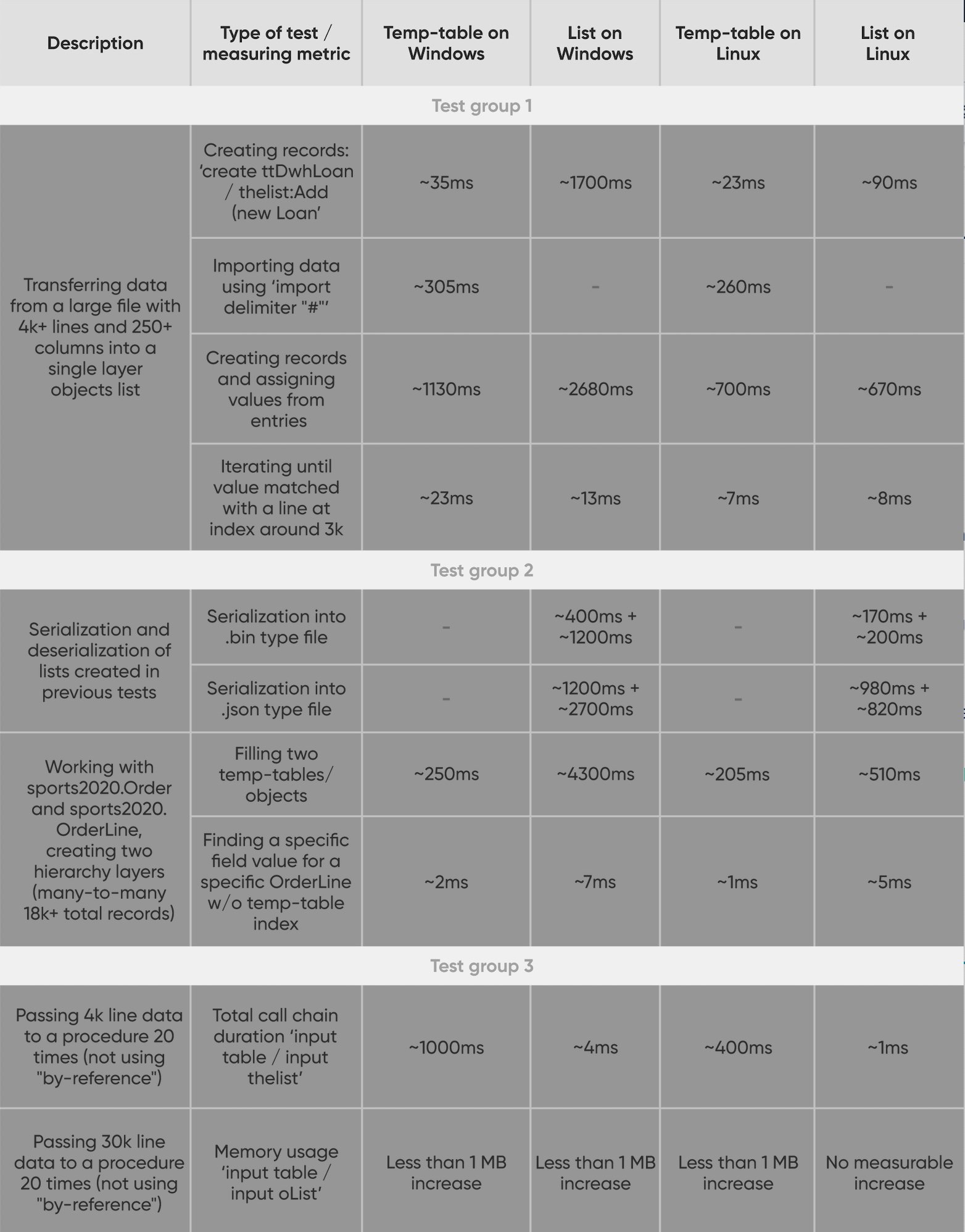
Conclusion
Test group 1: Temp-tables can be more efficient when reading large text files and in some instances in Windows, but overall, collections perform well;
Test group 2: Temp-tables can have a performance advantage working with many records. Data finding
performance is quite good with objects considering full scan;
Test group 3: Collections should have a significant advantage if a temp-table is not passed by reference.
If you need help with Progress OpenEdge application development, do not hesitate to contact the Baltic Amadeus team.

