In Part One, we discussed some of the more well known startup parameters. In today’s blog post, we’ll dig into parameters that are often used incorrectly or simply forgotten.
Table and Index Statistics
-basetable <#>, –baseindex <#>, –tablerangesize <#>, –indexrangesize <#>
By default OpenEdge only captures statistics for tables with _file._file-number between 1 – 50 and indexes with _index._idx-num between 1 and 50 (-basetable 1 -baseindex 1 -tablerangesize 50 -indexrangesize 50). Since most real databases have far more than 50 tables and 50 indexes, this usually this means that statistics are not being captured for most of your application tables, and none of the meta-schema tables. Without these statistics a lot of very interesting detail about application behavior is simply unavailable to you.
To quickly and easily get the optimal values for these parameters, download and run ProTop RT and view panel “T” – Show Table and Index Ranges. This will show you the suggested parameter values with and without meta-schema tables and indexes.

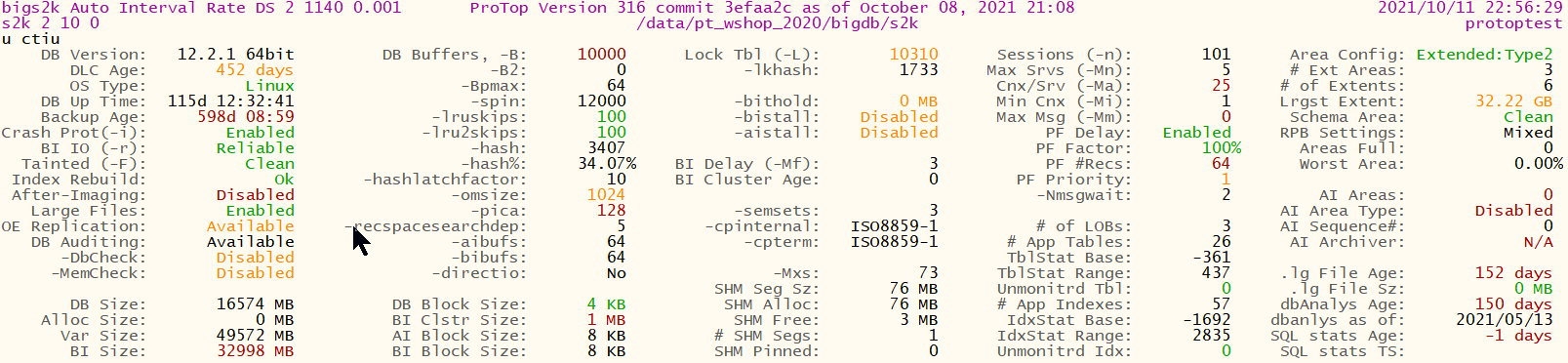
When you display the “T” panel, ProTop RT conveniently writes the the values to a file named <PROTOP DIR>/tmp/dbName.range.pf. Here is an example for a sports2000 database:
$ cat tmp/bigs2k.range.pf
# suggested table and index statistics settings for /data/bigdb/s2k
#
# basic (excludes system tables and some system indexes)
# -basetable 1
# -tablerangesize 76
# -baseindex 8
# -indexrangesize 106
# complete (includes system tables)
-basetable -361
-tablerangesize 437
-baseindex -1692
-indexrangesize 2835
Why doesn’t OpenEdge calculate these values automatically? Because the shared memory size calculation is done before the database is brought up but you need the database up to count the tables and indexes!
Windows Event Level (-evtlevel)
Typically, we set -evtlevel to none and use the database log files exclusively for database related messages. If you would like to see some database events in Event Viewer, set -evtlevel to “brief”, otherwise the thousands of login/logout and similar information messages will pollute your Windows logs.
Server -minport and -maxport
When connecting to a database using a client/server connection, a user process first connects to a broker listening port (the -S startup parameter). After authentication, the broker instructs the user process to reconnect on the listening port of a server process. When the broker spawns one of these server processes, a free TCP port between minport and maxport is assigned to the server by the operating system.
The minport/maxport range is most useful when client/server connections have to pass through a firewall, as it allows the network administrator to authorize access to a relatively small number of known ports.
Recommendations:
- Always set the range. Do not leave it to the default values
- Set the range to be comfortably larger than the -Mpb value (servers per broker) for that broker, as other processes may consume ports in that range.
- Use a separate port range for each broker. Overlapping port ranges will make it more difficult to troubleshoot connectivity issues
- Ports defined in the services file will not be used, even if the actual port is available for use. Compare your selected range versus the services file to make sure there are sufficient free ports.
- You may also want to add a comment to the services file, specifying the port ranges in use by OpenEdge. This will prevent a sysadmin from inadvertently using ports in your port range for something else.
Alternate Buffer Pool (-B2)
The alternate buffer pool is a very cool tool to pin database objects in shared memory. If the size of -B2 is bigger than the sum of all the tables and indexes assigned to it, the LRU latch mechanism is never activated for the alternate buffer pool, reducing CPU overhead related to accessing those tables. YMMV, but you may want to put frequently accessed small tables here (and their indexes!).
Two caveats:
- There are a few bugs that may cause the LRU mechanism to be activated for the alternate buffer pool. For example, see this KB entry and this KB entry.
- To check, look at the bottom of promon – R&D – 2 – 3 for the message “LRU2 replacement policy disabled”, or look for message 19380 “LRU on alternate buffer pool now established” in the database log file.
- With the advent of the lruskips parameter, reducing LRU latch activity and contention on the primary buffer pool, some of the use-cases for the alternate buffer pool may no longer be valid. Test, test and test some more.
Prefetch Parameters
-prefetchDelay: if not set, the first response will only contain one record
-prefetchPriority <#>: Prefer filling network messages with records over polling
-prefetchNumRecs <#> : The maximum number of records per network message. The default is 16.
-prefetchFactor <#>: The percentage fill factor for network messages. The default is 0.
These parameters apply to NO-LOCK PREFETCH queries, only, for example:
- FOR EACH … NO-LOCK
- DO PRESELECT EACH … NO-LOCK
- DEFINE QUERY q FOR table SCROLLING
- OPEN QUERY q FOR EACH table NO-LOCK
These parameters have no effect for FIND statements of any sort nor queries with share-lock or exclusive-lock. All of those have, at most, one record per message.
There is a series of YouTube videos coming out in Q4 2021 that will go into the gory details of client/server communications, but in the meanwhile, understand that the goal is to stuff as many records as possible into every network message.
Our recommendations:
-prefetchDelay -prefetchPriority 100 -prefetchNumRecs 9999 -prefetchFactor 100
Message Buffer Size (-Mm):
This is the size of each network message between client and database server. The default size is 1024 bytes and, per our benchmarks, incremental improvements flatten out around 16,384. It is particularly important to set this parameter to a large value when the prefetch* parameters are used, as the whole purpose of those parameters is to fill each network message with as many records as possible.
Note that even with the default network MTU of 1500 bytes, significant performance increases are seen when using a larger -Mm along with the prefetch parameters. Jumbo frames (MTU 9000) theoretically provide even more performance gains, but we have not recently done benchmarks to confirm this.
Note that prior to OpenEdge 11.6, both client and server must specify the same -Mm value, otherwise the connection fails. Starting with 11.6, the client accepts the value used by the database broker and, therefore, you no longer need to coordinate changes on both the server and the client. This makes deployment of -Mm changes much less painful! See this KB entry for more details.
Bonus Parameters
-DbCheck and -MemCheck
Our opinion on these parameters has changed over the past few years. When they first came out, it was not clear what effect they might have on performance, but today, we generally suggest using them for all databases. You can learn more about -MemCheck in this KB entry and -DbCheck in this KB entry.
Excess Shared Memory (-Mxs)
When starting a database, the primary broker calculates shared memory requirements based on start-up parameters then calculates adds an extra buffer amount “just in case”. This extra shared memory is used to increase the lock table when a lock table overflow occurs, or when the DBA issues a “proutil dbName -C increaseto …” command. Generally, we don’t suggest using this startup parameter unless there is a specific use for it.
Semaphore Sets (-semsets)
When more than 1,000 users connect to a single database, there might be high contention for the semaphore set. If there is a lot of semaphore contention on a system, using multiple semaphore sets helps alleviate this contention and improve performance on high user counts.
Recommendation – Our rule-of-thumb: 1 semset per 100 concurrent users.
Shared Memory Segment Size (-shmsegsize)
This parameter specifies the maximum size of a shared memory segment requested by the database broker from the operating system. By default, the broker will ask the operating system for one shared memory segment large enough to satisfy the calculated shared memory requirement.
Generally, we do not use this parameter, but it may be useful in situations where the amount of shared memory needed by that database is very large (in other words you have a large -B parameter). For example, on Windows, a shared memory segment must be allocated contiguously in memory. It may be possible to allocate 4 x 4 GB of contiguous shared memory, but not 1 x 16 GB. On very old releases of OpenEdge running on the Windows it was often necessary to set -shmsegsize 128 to get the db server to start but this has not been necessary with more modern releases.
If for some reason you are still using the 32-bit OpenEdge executables, there are even more constraints on total shared memory and the number of shared memory segments that a process can connect. For example, a 32-bit shared-memory client can only connect to databases with a sum total of shared memory less than 2 GB, and, on AIX, the total number of shared memory segments that a 32-bit client could attach could not exceed 11.
Gang-O-Useless
You probably don’t want to be using any of these parameters in OpenEdge 10 or higher !!
Direct IO (-directio)
Even when it was useful (v9) it was maybe only relevant on AIX. Today, you might hear of the occasional edge case where under very specific circumstances, on Fridays, when the moon is full, that this parameter somehow improves something. But probably not. If you would like to learn more, this KB entry might be of interest.
Delayed BI File Write (-Mf)
This is the maximum age, in seconds, of BI notes in the BI buffers. Once upon a time there was a reason to increase this on very busy systems, but that reason no longer exists. Leave the default of 3 seconds.
Cluster Age Time (-G)
Once again, a parameter from 15-20 years ago. This is the number of seconds before the database reuses a BI cluster. Do not set this parameter.
DB Buffer Hash Table Entries (-hash)
To find a block in the buffer pool, you need to search in the hash table to find the memory address of the block. Playing with this parameter can only cause pain and suffering, as detailed here and here. Do NOT set this parameter unless tech support instructs you to. Regularly check your conmgr.properties files for cases where it may have been accidentally set as a side-effect from other changes to conmgr.properties.
No Crash Protection (-i)
Do we really need to explain why you never want to use this parameter? If you run a database with this parameter and that database crashes for any reason, all of your changes WILL be lost. There is no recovery.
Non-raw (-r)
With the -r parameter, the database processes do buffered synchronous IO to the AI and BI files. For a production database, this is BAD: unbuffered synchronous IO ensures that changes to the database are immediately logged to disk, and those logs can be used for crash recovery. For a detailed discussion, see this KB entry.
However, -r can be useful when doing mass updates on a database that you can afford to throw away: for example, during a dump & load, you might want to use “proutil DB -C load <file.bd> -r”, understanding that if the server crashes during the load, your best option will be to throw the DB away and start over.
Next Steps
Now that you read part 1 and part 2, what do you do next? Check your parameter settings of course! To see them all in one place, use the free download of ProTop RT. The “C”onfiguration panel is colour-coded to show you parameter settings that might need your attention.
And if you’d like an independent opinion from some of the best OpenEdge DBAs in the world, contact us to schedule a review of your OpenEdge environment.