

If performance is not important to your database, you can stop reading.
On the other hand, if you are concerned about performance, the fundamental problem with SAN storage is that it is external and shared.
1. “External” means that your IO operations are at the wrong end of a cable and a bunch of adapters and switches.
OLTP database IO is random and in small blocks, it does not benefit from sequential, streaming or bulk performance optimizations. Every request is an individual round-trip – the storage subsystem cannot group them together and optimize them because they are unpredictable. You pay the additional latency penalty of that cable and all of the layers that the requests pass through with every IO operation. There is no cure for this.
Distance = time (1 nanosecond per foot in the best case). Network cables are obviously quite long as are the microscopic, but highly convoluted, circuit traces that your data flows through while it is chugging along through the chips inside of the devices handling it.
Handoffs = lots of time. In the very simplified diagram below every time your request goes from one layer of the stack to the next there is probably at least one queue involved, data is probably being copied between memory locations, a scheduler had to get involved and quite a lot of logic was executed. All of those operations take time.
For a human-scale analogy imagine the difference between getting your weekly groceries by going to the store, filling up your cart, checking out, loading the car, driving home and then unloading the groceries. Maybe you can even get those groceries delivered if you live in the right neighborhood. That is similar to streaming IO.
Now imagine that the list is not known to you – every item is requested randomly as soon as you unload the previous item (perhaps you have teenagers at home). If the grocery store is in the same building that might not be too bad. The path is short and you probably needed some exercise anyway. This is random IO to an internal device.
Next imagine you have to get in the car and drive half an hour for each random item and that you have to wait in line to show the list (with one item on it) to a clerk when you get to the store (no, you cannot call it in – you are driving at the speed of light). After making a copy of your one item list, the clerk who has been optimized to fetch truckloads of groceries with every request, scoots away with a forklift to get your carton of eggs. And, of course, the clerk still has to queue for the checkout. You also probably had to queue at toll booths on the highway between your house and the store. Both ways. To say nothing of the traffic lights. And rush hour. This is random IO to an external shared device. You can probably see why minimizing handoffs is important.
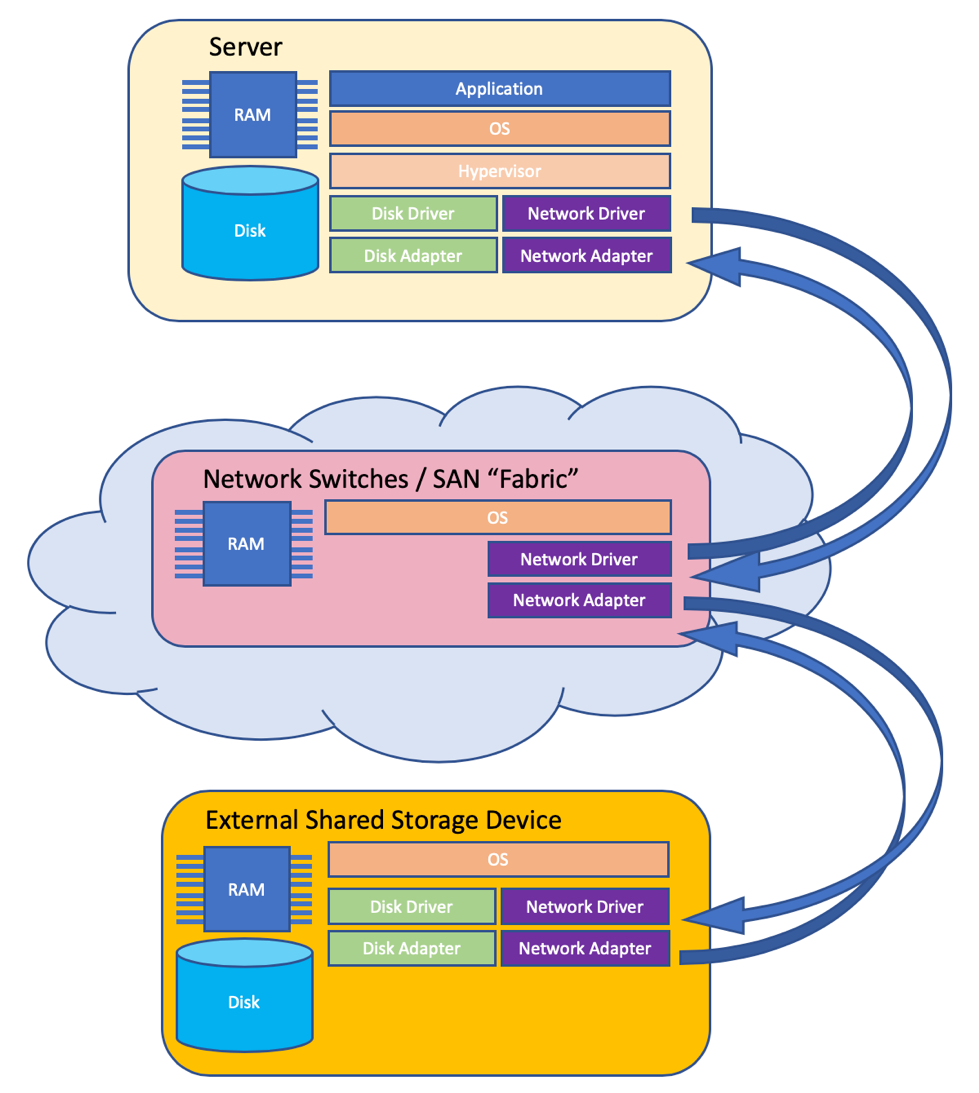
1a. Just in case you expect “all flash” to cure all of your performance problems — putting SSD at the wrong end of a cable does not address any of the latency in the cable and the adapters. It will help with the rotational latency of spinning rust disks but that is just a part of the problem – and one that was already being handled by the cache in the storage system. So, don’t expect to see much improvement from an “all flash” SAN.
2. “Shared” means that you have competition for resources.
Your database will not get 100% of the available bandwidth. Backing up the Exchange server will have a higher priority (anything that does lots of sequential IO will have higher priority — that kind of thing is what these devices are designed for). Lots of people who have no knowledge of your busy times and who have even less sensitivity to the impact that they are having on your performance will feel perfectly free to launch massive IO jobs right in the middle of your peak processing times.
3. These devices do not exist to make your database go faster. Their purpose in life is to consolidate workloads, save space and power in data centers, and simplify the lives of storage administrators. That is all very admirable but the trade-off is that it is not compatible with a high-performance database.
4. If database performance is your #1 priority then you want the shortest path from the CPU to the data and back. That means a device which is internal to your server. (Coincidentally internal SSD* is also often a lot less expensive than a fancy SAN.)
5. If you already spent a whole bunch of money and bought a fancy storage subsystem that is slower than you hoped it would be, the only thing that can be done about that (aside from using it for something else and going with internal SSD instead) is to load up the server with as much RAM as possible and avoid IO ops for as long as possible. Which is a big part of normal database tuning so you have likely already done that.
5b. Even if you have a huge RAM cache and hardly ever perform an actual IO operation during normal processing you will still have to perform IO at times and at some of those times it will be very, very painful. Index rebuilds, dump & load, backup and restore, roll-forward recovery, re-baselining replication, running dbrpr to fix corruption are all activities where there is a lot of time pressure and where the pain of having an inappropriate storage solution is most keenly felt. I hope that you never have to recover a corrupted database with a bunch of senior executives asking “is it done yet” – but if you do you will be very unhappy to have to do it with a sub-par IO subsystem.
6. You can sometimes improve SAN devices from “horrid” to merely “bad”. Storage devices all have complex sets of vendor specific configuration options and there are many tradeoffs that can be made. The default configuration is not focused on OLTP databases and, as a result performs poorly. For example, a system that is used as a file-server has many creates and deletes of files and modifications of file metadata whereas a database server has very few of those operations and is mostly doing random reads and writes to a relatively small set of files.
ProTop Can Help
ProTop has two features that are specifically designed to help you troubleshoot IO performance issues. These two metrics are: ioResponse and syncIO.
ioResponse is an end to end measurement of random read performance as seen by the OpenEdge application.
It is common for storage vendors to claim that there are no problems with their solution because their tools are telling them that “everything is fine”. Often, they will provide data regarding disk utilization or response times generated from within their device. The problem with that is that it is not an end to end perspective. It is just one isolated data point taken from the middle of the IO journey that your requests are on. It is also probably averaged data that includes everyone else’s requests. If that wasn’t bad enough, in many cases, the overwhelming majority of those other requests are bulk IO operations and those operations will dramatically skew the averages.
The ProTop ioResponse metric is calculated by seeking to random offsets in large files and reading one byte. The average round trip response time is then calculated. By default, the large files are your largest database extents. This ensures that the disks being probed are the same as your database disks. In most cases the database extents are also going to be large enough that the file data is not being completely cached and the random seeks will go to uncached locations.
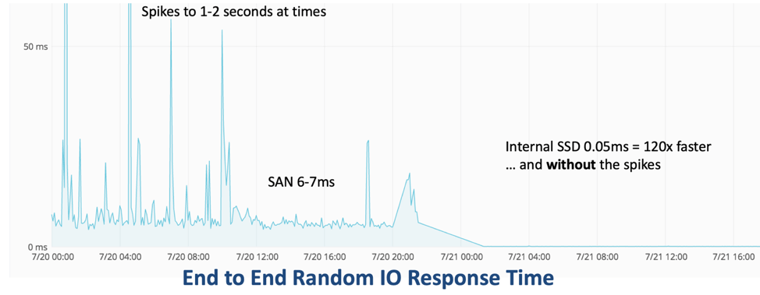
The chart above shows the performance of a typical SAN on the left and its replacement with internal SSD on the right. Some SAN’s are much worse than this and NAS devices are usually very much worse. Modern internal rotating disks are usually around 2ms.
We have historical data for thousands of databases and there are very clear patterns in that data. We can immediately tell what sort of hardware a customer has just by looking at the ioResponse chart and when we see slow, spikey ioResponse we know that there are serious issues that need to be addressed.
Of course, not all database activity is reads. You also write data – that is how your database gets to be so big. Just as they do for reads, storage subsystems have many optimizations for writes. Unlike many other applications a database must ensure that data has actually been written to disk and that those writes have occurred in the correct order. OpenEdge uses synchronous writes for those operations. If OpenEdge did not do so write performance could be much better but data integrity would be compromised.
ProTop’s syncIO metric measures how long it takes to grow 96MB of bi clusters synchronously. This is a very important indicator of limitations on write performance and, just as with ioResponse, there are clear differences between internal SSD and SAN deployments:
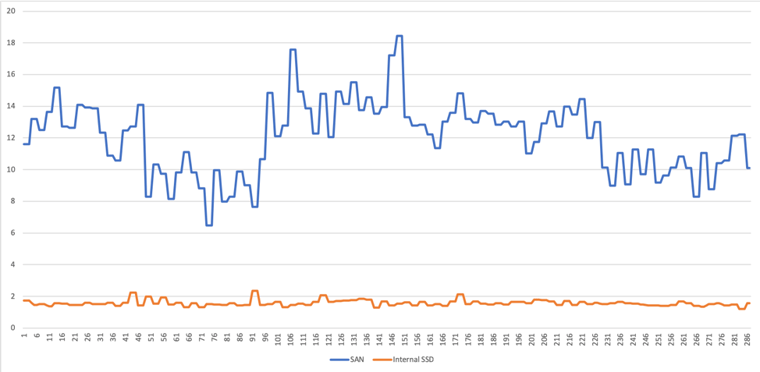
In the same manner as ioResponse this is an end to end metric, as your OpenEdge application sees it, rather than an isolated data point. Just as with ioResponse we see a large number of systems and the comparison above is very typical. SAN storage is always substantially slower and less consistent than internal storage.
This does not mean that every workload in your data center should go to internal SSD. But your performance critical databases certainly should. Yes, there are some negative trade-offs. You cannot, for instance, use SAN based tooling to allocate, backup, and manage your internal storage. But if performance is your #1 goal internal SSD is unquestionably faster, more consistent and less expensive than SAN storage.
The storage vendor will, of course, deny all of the above and try to claim that OpenEdge is somehow deficient**. Or that I am a luddite. Or both. Keep in mind that the sales guy is earning a commission. I am just performing a public service.
* For the purposes of this paper there are many solid-state storage technologies that loosely fall under the banner of “SSD”.
** The ProTop tools happen to be written in Progress 4GL and they are obviously focused on OpenEdge. But we are not alone! Many other people running many types of applications have experienced similar problems and it is not difficult to find similar tools written for other environments. We can easily use “dd” (a common UNIX tool) to show the syncIO issues without any Progress involvement. Likewise, there is simple “C” code available that will perform the ioResponse test. We use Progress because it is always available on whatever platform we are running on.
For more information on ProTop, visit our new ProTop website or book a demo to see it in action.
Download ProTop today!

